在现代社会,无论是在工作还是在学习中,数据的处理和分析能力显得尤为重要。Excel作为一款功能强大的电子表格软件,因其简便易用和强大的统计分析功能,成为人们日常统计和整理数据的首选工具。其中,统计某些数据出现的次数,是Excel常见而实用的功能之一。本文将围绕“excel统计出现的次数”这一主题,结合中国地区的实际应用场景,详细介绍如何利用Excel高效统计汉字或其他数据的出现次数,帮助广大用户更好地掌握这一技能。
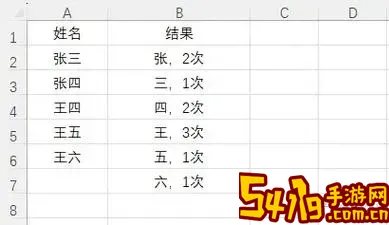
在中国的办公环境中,Excel被广泛应用于财务、销售、人力资源等多个领域。例如,销售人员需要统计某个产品销售的次数,教师需要统计学生某次作业中指定字词的出现频率,企业人事部门需要统计员工的某项技能出现次数等等。统计“出现的次数”不仅能够帮助用户快速掌握数据情况,还能为决策提供重要依据。尤其是对于汉字的统计,由于汉字的特殊性,与英文字符统计有所不同,因此掌握适合的方法显得尤为重要。
首先,针对Excel中统计汉字出现次数的问题,我们可以使用函数来实现。最常用的方法是利用“LEN(长度)”函数结合“SUBSTITUTE(替换)”函数。具体步骤如下:
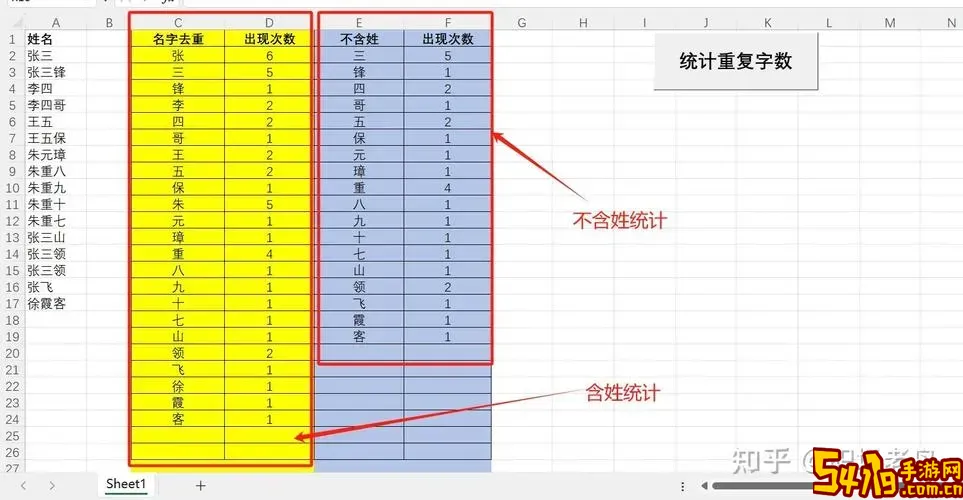
假设A1单元格中有一段包含汉字的文本,我们想统计其中某个汉字“中”出现的次数,可以使用以下公式:
=(LEN(A1)-LEN(SUBSTITUTE(A1,中,)))/LEN(中)
这里的原理是:先计算A1单元格文本的总长度,再用SUBSTITUTE函数将文本中所有“中”替换为空字符,计算替换后文本的长度,然后用总长度减去替换后长度,差值即是“中”这个汉字在文本中总占用的字符数,最后除以该汉字本身的长度(一般是1),得到实际出现的次数。
这种方法的优点是简单高效,适用于统计单个汉字或短语的出现次数,而且可以嵌套在其他Excel函数中,方便批量处理。缺点是在处理超大数据时,计算速度可能有所下降。
其次,在实际操作中,用户可能需要统计多个不同汉字的出现次数。为此,可以通过Excel的“数据透视表”结合VBA编程实现更为复杂的统计。例如,通过编写宏,将指定范围内的文本内容拆分统计,生成汉字频率统计表。
以中国语言研究机构和文化传播部门为例,统计报纸、文学作品中汉字的使用频率,为汉字推广和教学提供数据支持。具体实现可以通过扫描文档数据,导入Excel表格后,利用上述统计原理快速得到每个汉字的出现频率。这种统计对于语言学研究、新词发现以及文本可视化分析有着重要意义。
再者,伴随着人工智能和大数据技术的发展,Excel配合Python等编程语言也成为汉字统计的新趋势。相比单纯使用Excel函数,Python的pandas库和jieba分词库可以实现更精准、智能的汉字词频统计和文本分析,尤其适合处理海量数据。然而,对于日常办公用户来说,掌握Excel内置函数统计汉字出现次数依旧是快速高效的基础技能。
此外,在实际应用中,准确统计汉字出现次数还需注意文本编码和格式。一些文本由于编码方式不同可能导致汉字识别异常,影响统计结果。用户应确保Excel文件及输入内容采用UTF-8等通用编码格式,避免乱码。同时,注意排除无关符号、空格等干扰字符,以使统计结果更为准确。
总之,掌握Excel统计汉字出现次数的技巧,对于提升数据分析能力和办公效率都有极大帮助。本文介绍了基于LEN和SUBSTITUTE函数的简单统计方法,结合中国地区办公场景,阐述了其广泛应用价值和注意事项。未来,随着技术不断进步,汉字统计将更加智能化和多样化,但Excel依然是每个中国职场人不可或缺的利器。希望广大用户多加练习,灵活运用,充分发挥Excel在汉字数据统计中的强大功能。